Some Initial Thoughts on Llama 4 Models
Meta Releases Llama 4: Pushing the Frontier with Long Context Models
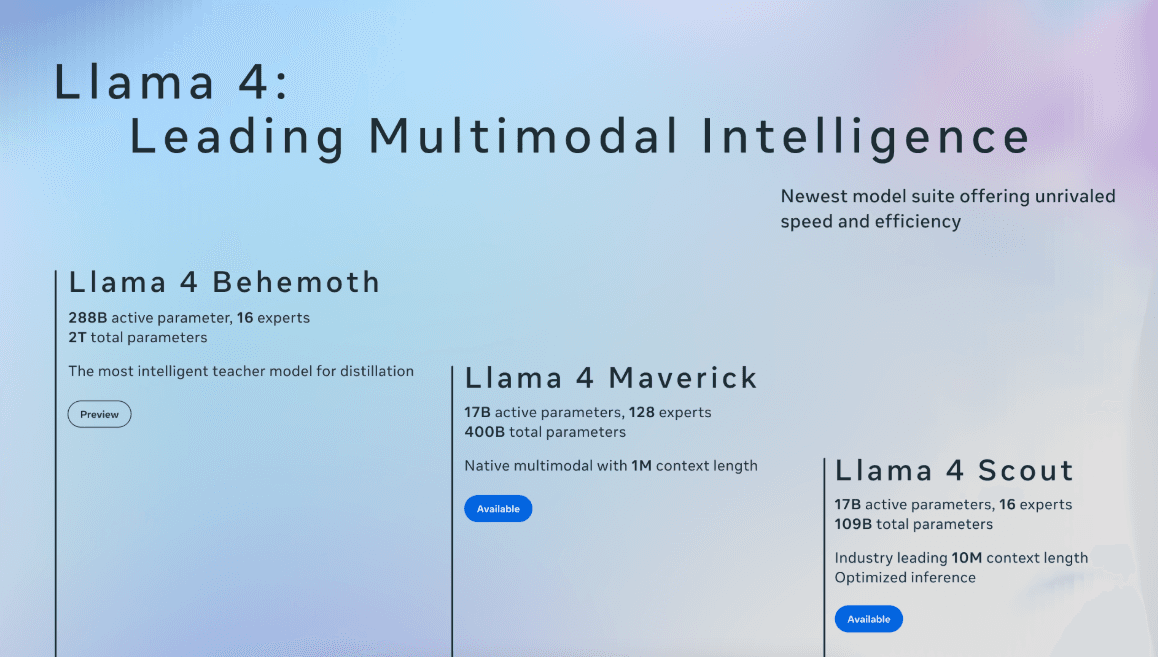
Meta has once again pushed the boundaries of generative AI with the release of Llama 4, introducing revolutionary models like Llama 4 Scout and Llama 4 Maverick. Notably, these models are fully open-weight, continuing Meta’s commitment to openness and innovation within the AI community.
A New Era of Long Context AI
The standout feature of the Llama 4 models, particularly Llama 4 Scout, is their extraordinary context length—capable of handling an industry-leading 10 million tokens. To put that into perspective, you could fit the entire Harry Potter series (~1.4M tokens), India's Income Tax Act and GST documentation (~2M tokens), or the entire Indian Penal Code (~0.3M tokens) comfortably within this model's context window.
Initial Thoughts & Practical Implications
Focus on Foundation: While recent AI hype has heavily centered around advanced reasoning capabilities, Meta interestingly chose to refine the foundational base model itself with Llama 4. This strategic choice hints at a deeper commitment to building reliable and robust base models—perhaps paving the way for advanced reasoning abilities in future iterations.
Resource Requirements: Running the Scout variant with just 1M tokens of context—despite its ability to handle up to 10M—requires approximately 110GB of VRAM, assuming fp8 precision. Such demanding hardware specifications mean that these models are out of reach for typical consumer GPUs.
Consumer Accessibility: Unfortunately, this level of innovation comes with significant hardware costs, placing it beyond standard consumer hardware capabilities.
Is 10M Context Practical?: Although impressive, practical use cases requiring a 10M-token context length are likely rare. Most real-world applications would find a 1-2M token window more than sufficient, covering complex legislative texts, extensive literature, and comprehensive codebases.
Cost Efficiency: A significant advantage of Llama 4 models is the reduced inference cost, being approximately 1/10th to 1/25th of the cost of GPT-class models, depending on the provider. However, practical deployment would depend on the specific requirements and use case.
Ideal Use Cases for Llama 4
Given the vast context lengths and lower inference costs, some compelling practical applications include:
- Legal Tech & Compliance: Handling extensive documentation, such as regulatory frameworks and legal codes, providing rapid referencing and summarization.
- Enterprise Knowledge Management: Parsing massive internal knowledge bases, enabling detailed query responses, personalized recommendations, and internal knowledge retrieval.
- Advanced Coding Assistance: Reviewing, analyzing, and debugging extensive code repositories, significantly improving developer productivity.
- Academic and Literature Research: Assisting in deep literature reviews, where summarizing and cross-referencing extensive documents is essential.
How to Access Llama 4 Models
Both Llama 4 Scout and Llama 4 Maverick are available for download now via llama.com and Hugging Face. Meta is further integrating these models into its suite of applications, including WhatsApp, Messenger, Instagram Direct, and the Meta AI website, providing immediate opportunities to explore their capabilities
Need help building AI into your product?
We design, build, and integrate production AI systems. Talk directly with the engineers who'll build your solution.
Get in touchWritten by
Aniket Kulkarni
Aniket Kulkarni is the founder of Curlscape, an AI consulting firm that helps companies build and ship production AI systems. With experience spanning voice agents, LLM evaluation harnesses, and bespoke AI solutions, he works at the intersection of engineering and applied machine learning. He writes about practical AI implementation, model selection, and the tools shaping the AI ecosystem.
Continue Reading

OpenAI API Pricing Guide 2026: Every Model Compared
Every OpenAI API model priced and compared for 2026, from GPT-5.2 to o4 Mini. Includes real-world cost calculations for chatbots, pipelines, and more.

The Hidden Math of Text: A Guide to Quantitative Analysis

Fine-Tune an LLM to Mask PII in 2 Hours with Axolotl — Step-by-Step Tutorial
Learn to fine-tune an LLM for PII redaction using Axolotl and Modal. Step-by-step tutorial covering QLoRA, dataset preparation, and production deployment for GDPR compliance.